Keyword [ESPCN] [Pixel Shuffle] [Optical Flow] [FlowNet]
Sajjadi M S M, Vemulapalli R, Brown M. Frame-recurrent video super-resolution[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2018: 6626-6634.
1. Overview
目前的視頻SR任务使用CNN+motion compensation方法,通过多个LR帧生成一个LR帧。当前State-of-art方法使用sliding window实现,但存在缺陷:
- 计算冗余. 多帧被重复计算
- 独立估计每帧. 限制了temporally consistent results
因此,论文提出frame-recurrent video super-resolution (FRVSR)框架,previous HR estimate参与到当前帧的预测 (optical flow warping)
- Temporally consistent result
- 降低计算量. 相比于sliding window, 每帧只计算一次
- Assimilate a large number of previous frame
- No pre-train, end-to-end
- 处理任意size, length视频
1.1. 模型


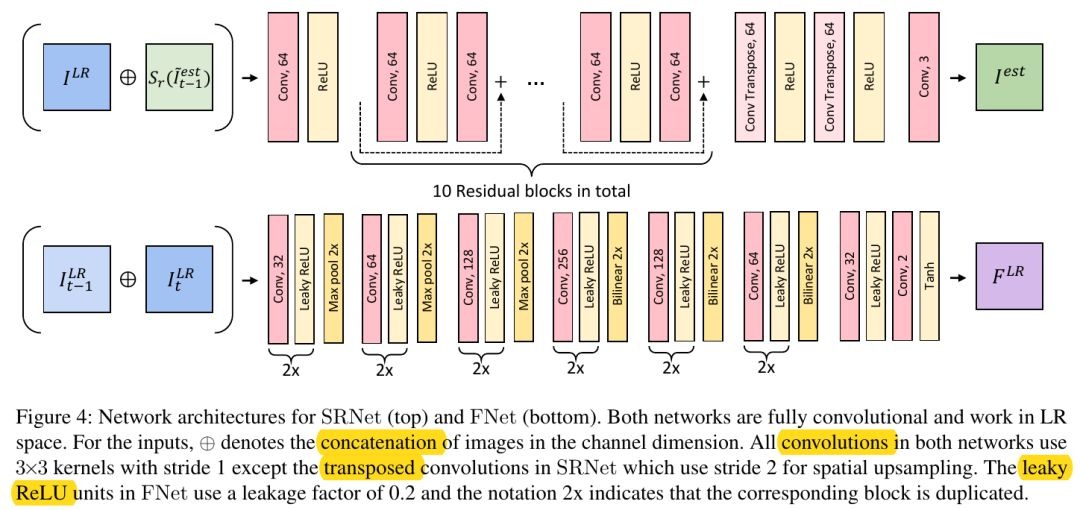
1.2. 数据集
1.2.1. 训练集
- vimeo.com下载40个HR视频,downsmaple 2倍
- Extract 256x256 patch
- Gaussian blur. 方差1.5
- 提取相似场景连续帧
1.2.2. 测试集
- youtube.com下载3-5s HR视频(YT10)
1.3. Future Work
- Occluded region
- Application. video compression
- Loss term. GAN, EnhenceNet.
1.4. 相关工作
- Interpolation
Bilinear, Bicubic, Lanczos - Example-Based
- Dictionary Learning
- Self-similarity
(Deep Learning)
- GAN
- Multi-frame (Expensive)
- Optical Flow
- Conv-LSTM
- Bidirectional Recurrent Architecture
2. Experiments
2.1. Baseline
- SISR. LR输入SRNet
- VSR. sliding window, warp t+1, t-1 to t帧, concate输入SRNet
2.2. 实验结果


2.3. Blur Size

2.4. Training Clip Length

2.5. Degraded Input

2.6. Temporal Consistent

2.7. Range of Information Flow


2.8. Network Size
